UE-TSet
概述
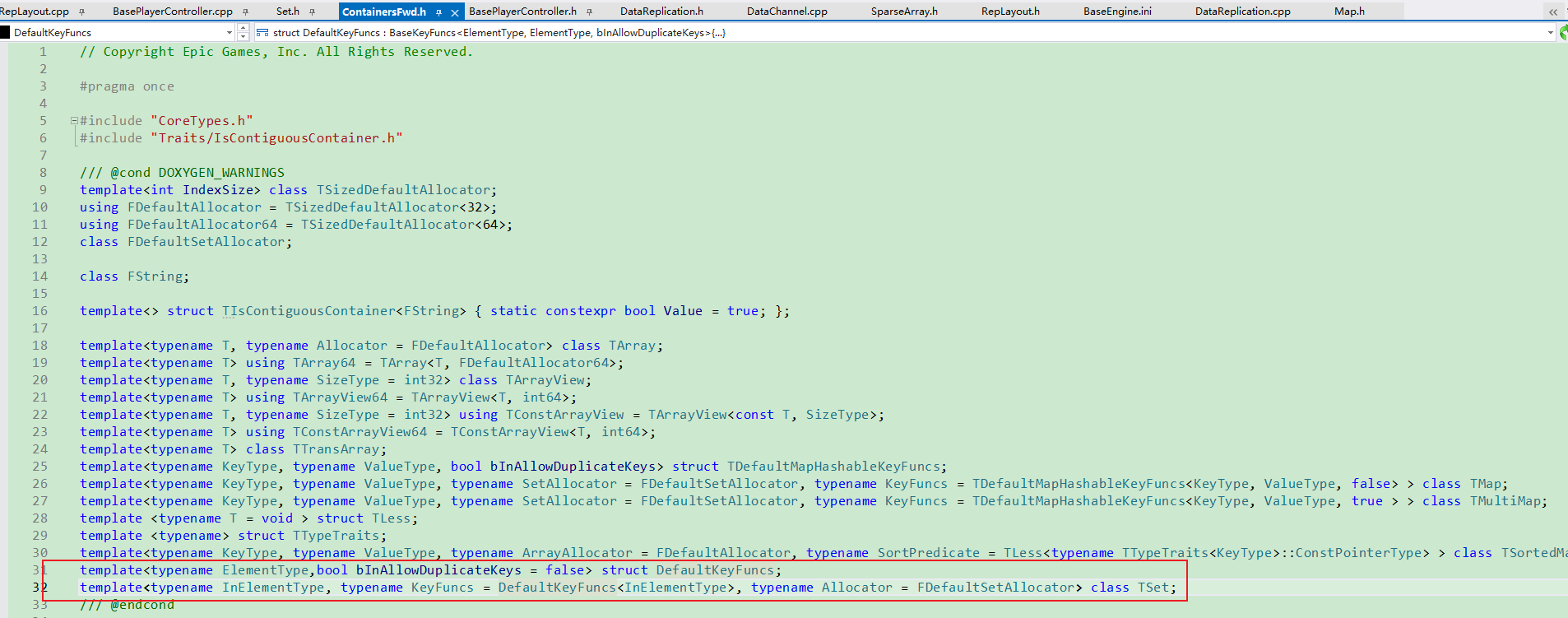
核心: HashArray+ElementArray.
即可以理解成TSet由两个层组成,Key层(索引层)+Value层(值层).
- Key层存储着Hash/Size之后的值, 用于定位Value层数据.
- Value层存储这所有数据. 其本身是无序的. 对于同一个Key的不同Value, 其用链表方式链接
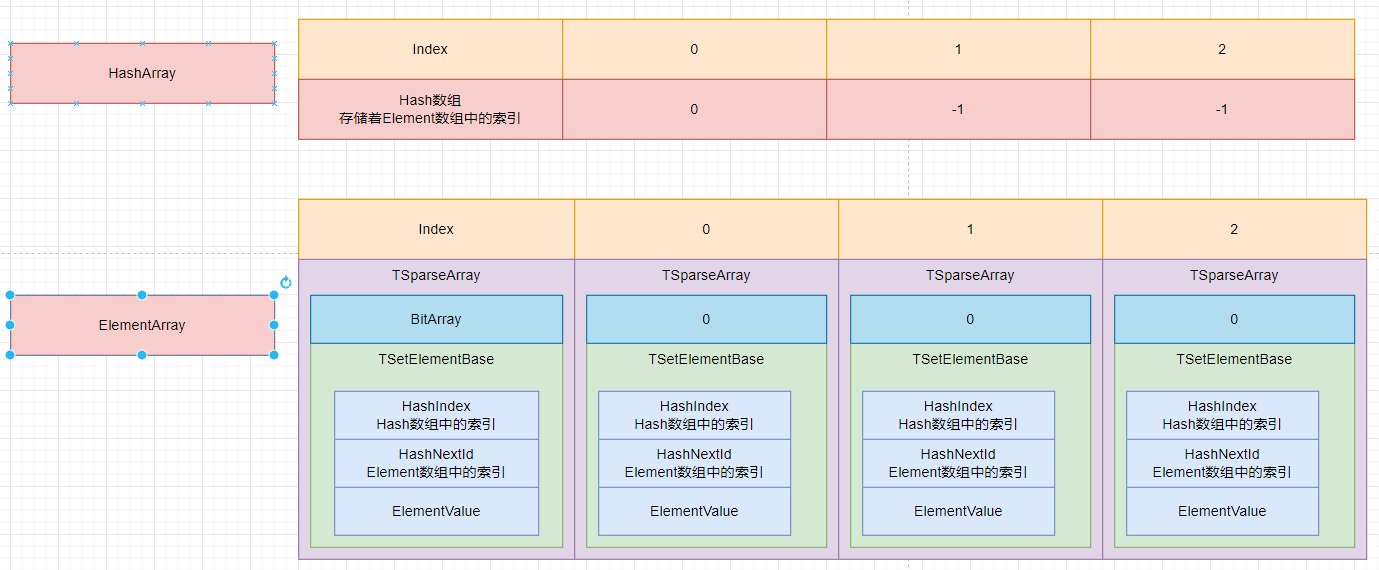

一般Hash的实现一般由以下步骤实现:
- 将Element映射成Hash.
- 通过Hash值找到对应成员.
具体实现:
UE使用两个数组HashArray+ElementArray来实现TSet,
HashArray中存放着ElementArray的Index,
ElementArray中存放着具体的值.
- TSet将映射方式暴露给用户,
由程序员自定义实现:
uint32 GetTypeHash(...), 最终返回类型为uint32的KeyHash. - TSet内部实现了通过
KeyHash找到对应Element的方式:- 根据
HashIndex & (HashSize - 1), 计算HashIndex, 然后取出HashElementValue, 此处HashElementValue代表ElementArray的Index. - 根据
Index从ElementArray获取具体的ElementValue, 如果发生冲突, 拉链法解决冲突. 每个Element记录着NextElementIndex, 如果该Element发生冲突, 通过NextElementIndex寻找到下一个Element.
- 根据
实现细节
声明
前置声明,
默认使用DefaultKeyFuncs<InElementType>作为KeyFuncs,
使用FDefaultSetAllocator作为Allocator
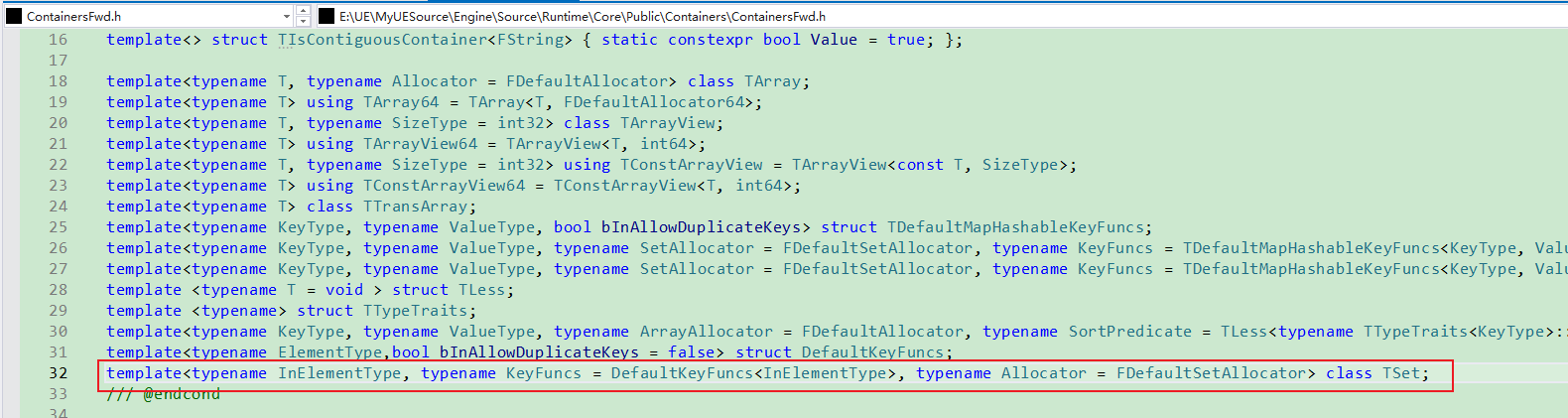
真正实现:使用四个传入参数作为TSet的模板参数.
Add
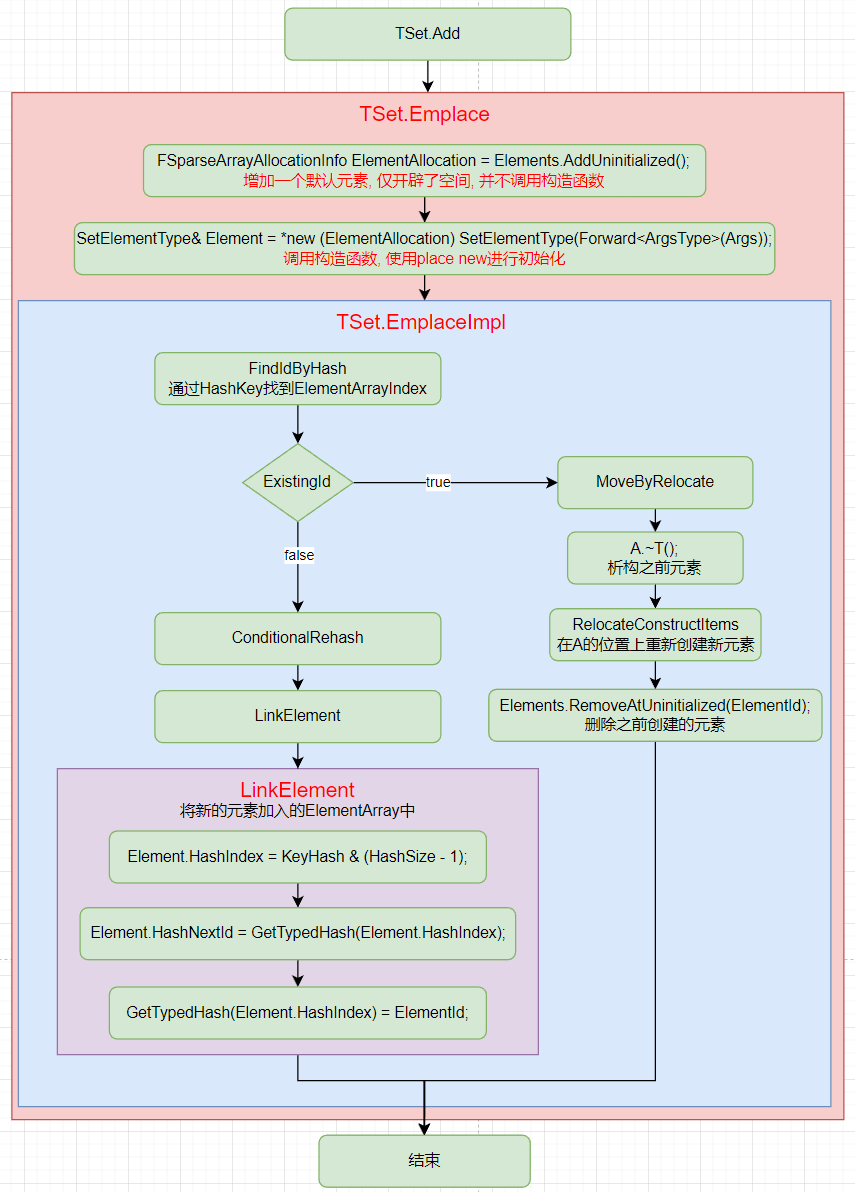
TSet.Add
调用Add函数TSet.Add添加元素.

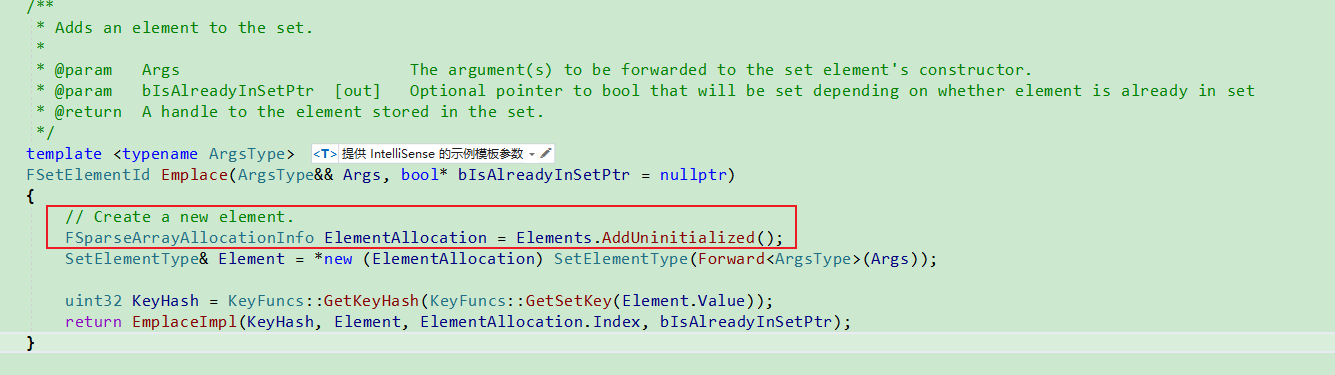
TSet.Emplace
进一步调用TSet.Emplace.
在Elements中添加元素,
然后根据参数进行初始化(place new).
根据ElementValue获取Hash值.

根据Hash值,
获取Hash数组中的索引HashIndex & (HashSize - 1),
根据Hash索引, 取出Element

TSet.EmplaceImpl
调用TSet.EmplaceImpl, 实现真正Add.
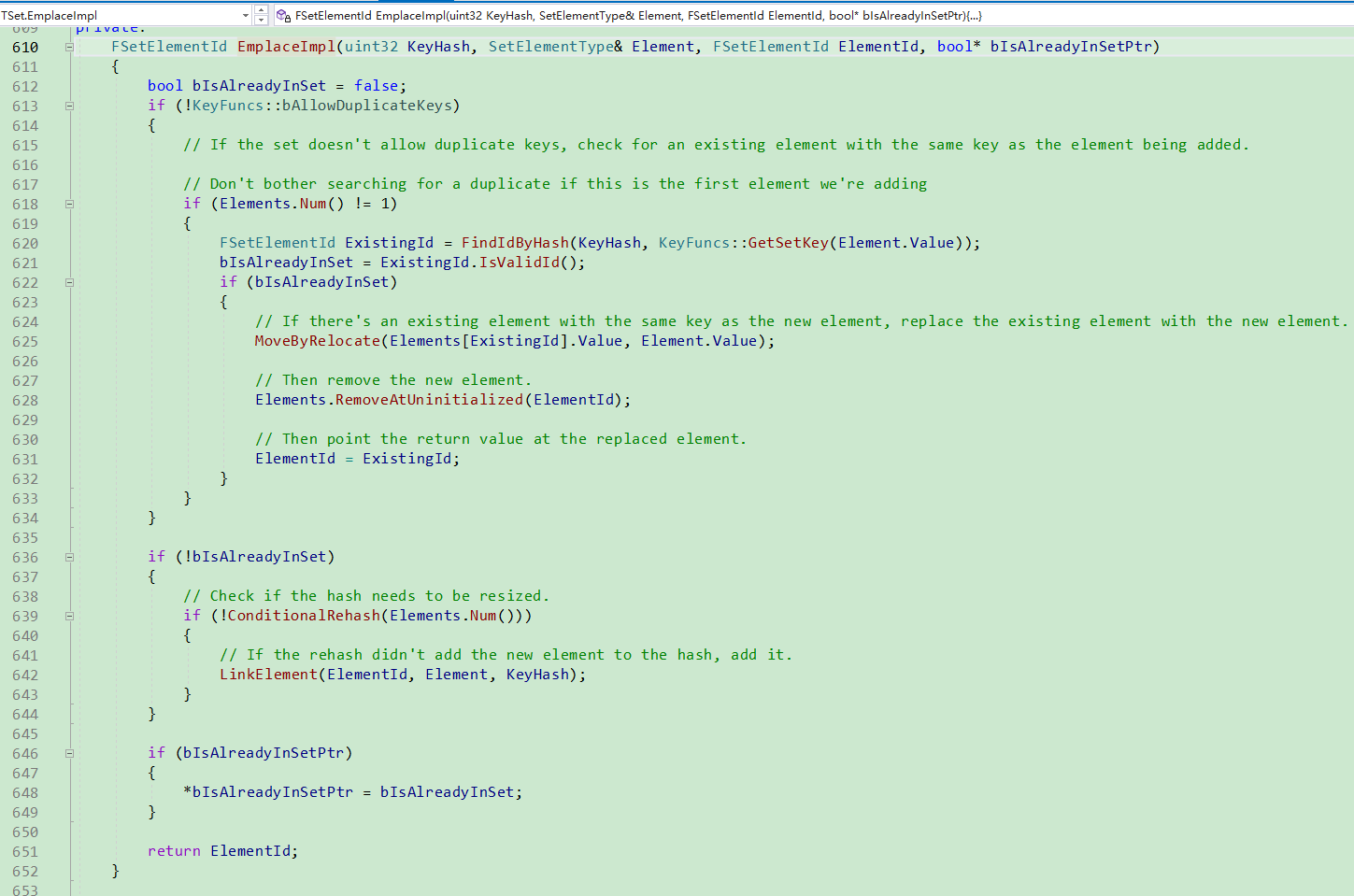
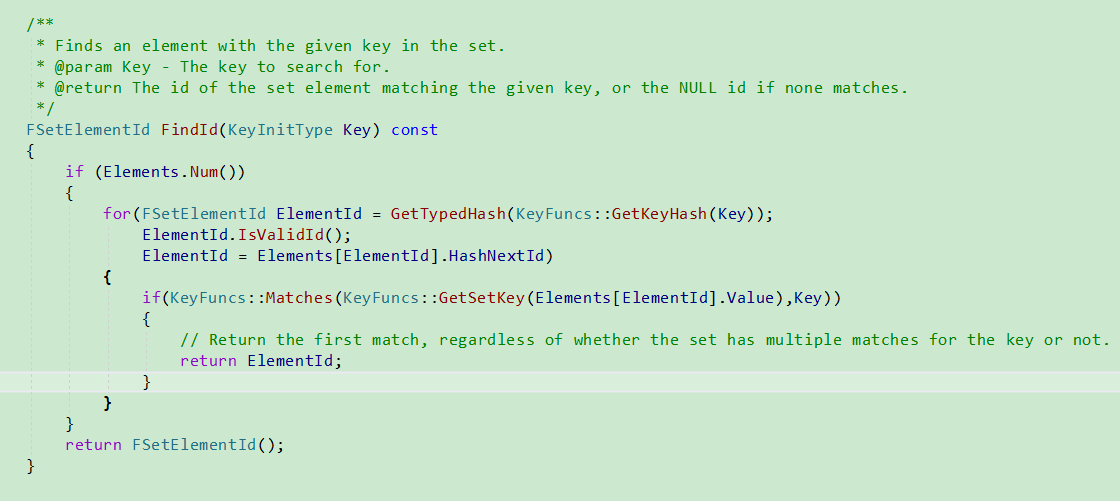
讲解一下该函数中的FindIdByHash函数.
通过KeyHash获取到ElementArray中指定元素.
由于不同元素可能定位到同一个ElementIndex上,
UE使用拉链方式解决冲突,
它根据TSetElementBase.HashNextId构成一个链表, 进行存储.
所以需要遍历这个链表, 比较每个元素是否真正相同. 如果真正相同,
则返回其ElementIndex.

如果ElementArray存在对应的元素, 就覆盖, 否则,就添加新的.
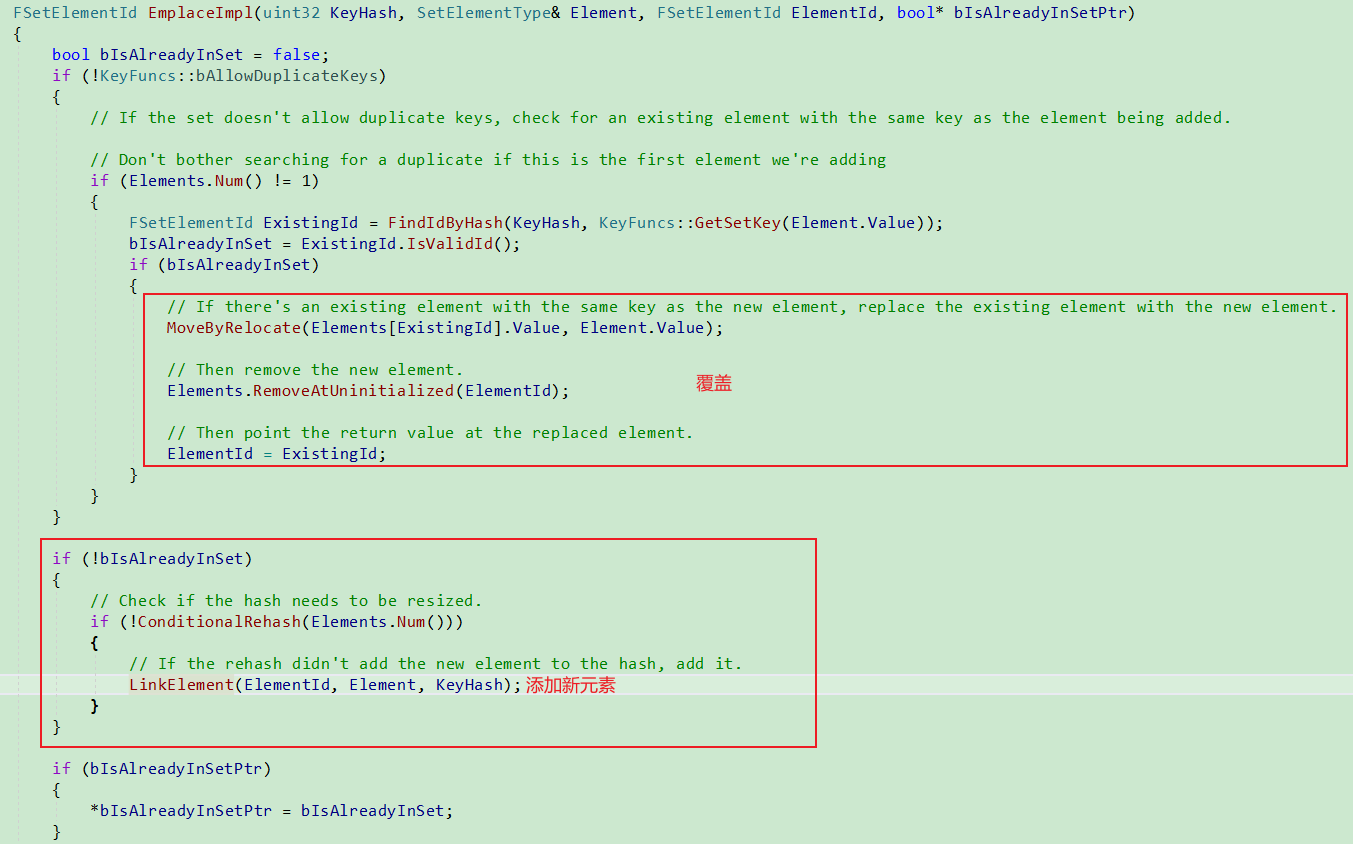
添加新元素时, 将新元素插入到链表首位.
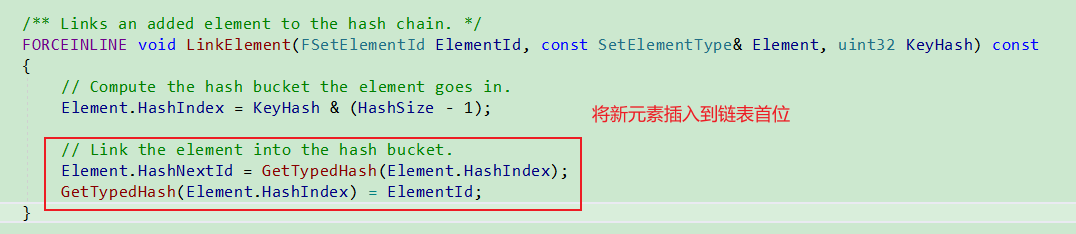
注意: 在Add时候会返回之前元素是否已经存在.

Find
首先根据Element生成KeyHash, 根据KeyHash找到HashArray中的Index,
根据ElementIndex(HashArray[HashIndex])定位到ElementArray中的元素,
即链表头, 然后遍历链表, 通过比较方式找到最终的对象.
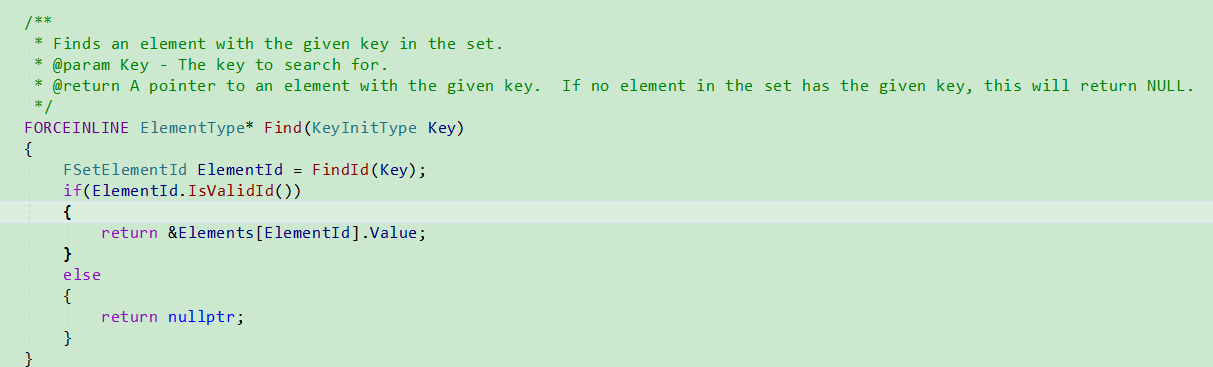
找到最终的Element元素索引.
Contains
根据Key(Element本身)计算出KeyHash,
通过KeyHash& (HashSize - 1)得到HashIndex,
取出HashArrayItem(即ElementIndex),
遍历ElementArray中的链表, 查看其是否真正存在.


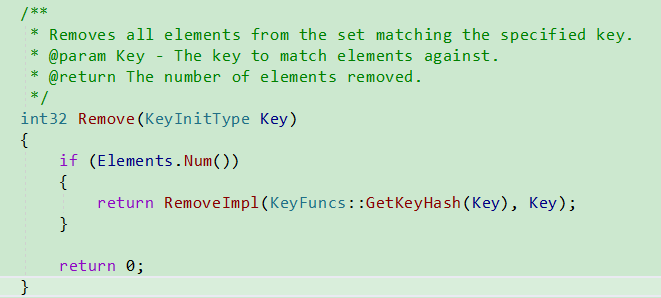
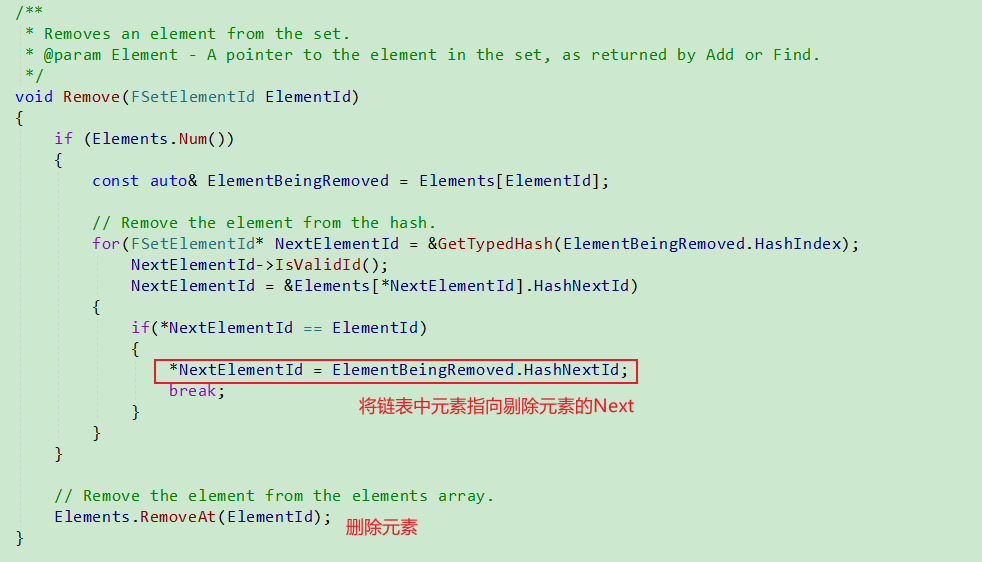
Remove
调用TSet.Remove函数,
使用KeyFuncs::GetKeyHash(Key)计算其KeyHash,
并传入到TSet.RemoveImpl中.
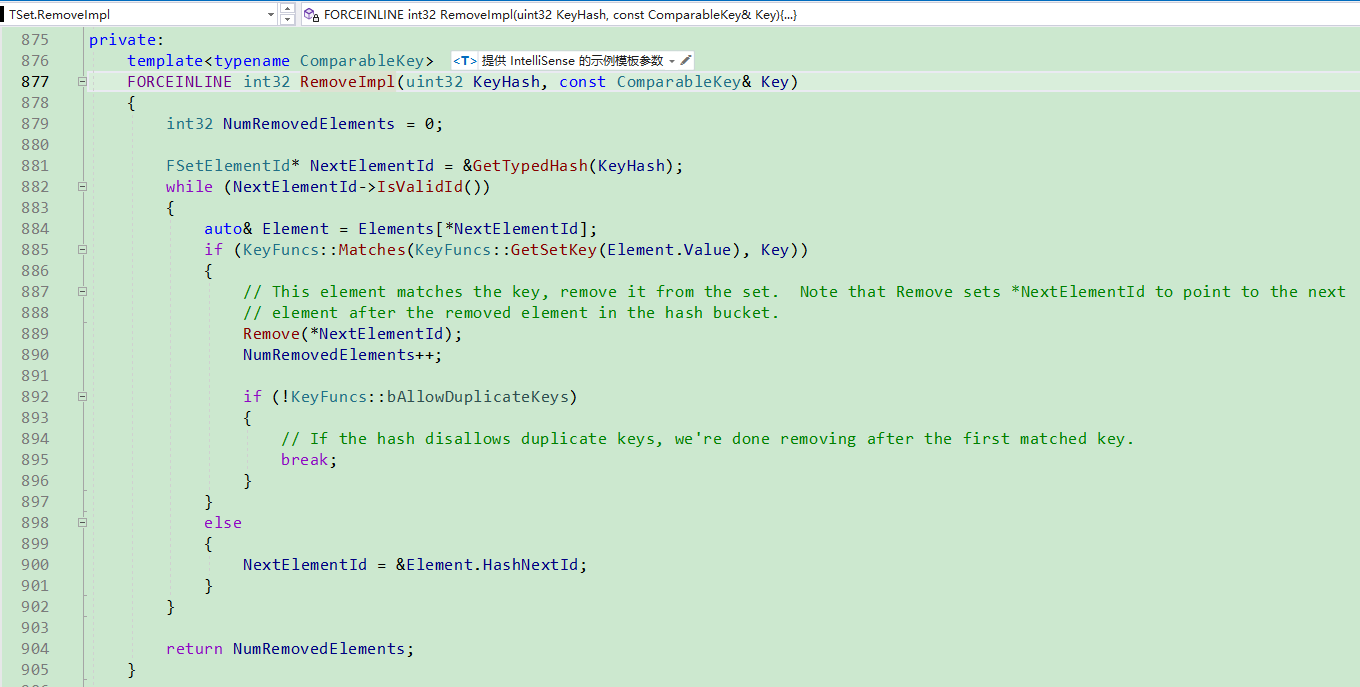
在函数TSet.RemoveImpl中,
使用函数GetTypedHash(KeyHash)计算其ElementArrayIndex,
然后开始该遍历. 使用比较函数KeyFuncs::Matches, 如果相同,
则直接删除, 如果bAllowDuplicateKeys为false, 则直接break,
否则继续遍历.
注意一点, 当bAllowDuplicateKeys为true的时候,
是删除了NextElementId指向的元素,
NextElementId并没有删除,
这就是为什么NextElementId使用指针的原因. 否则代码会非常乱,
没有现在这么简洁
使用void Remove(FSetElementId ElementId)函数,
真正删除对应的元素.
链表删除逻辑:
- 存储next指针, 指向待处理元素.
- 通过比较, 检测是否为待删除元素A, 如果是, 则将Next指针的值设置为A的next, 并进行break; 否则继续遍历.
- 删除元素A.
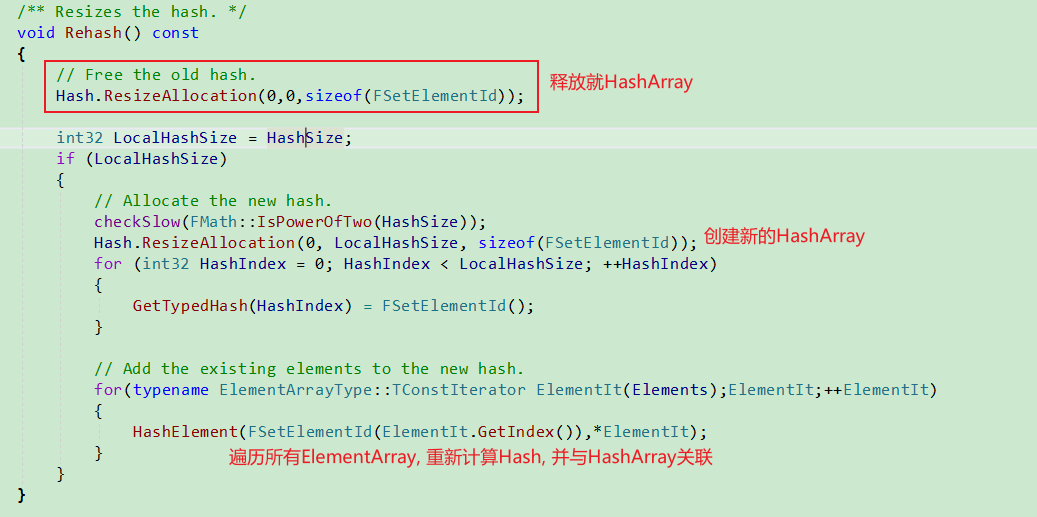
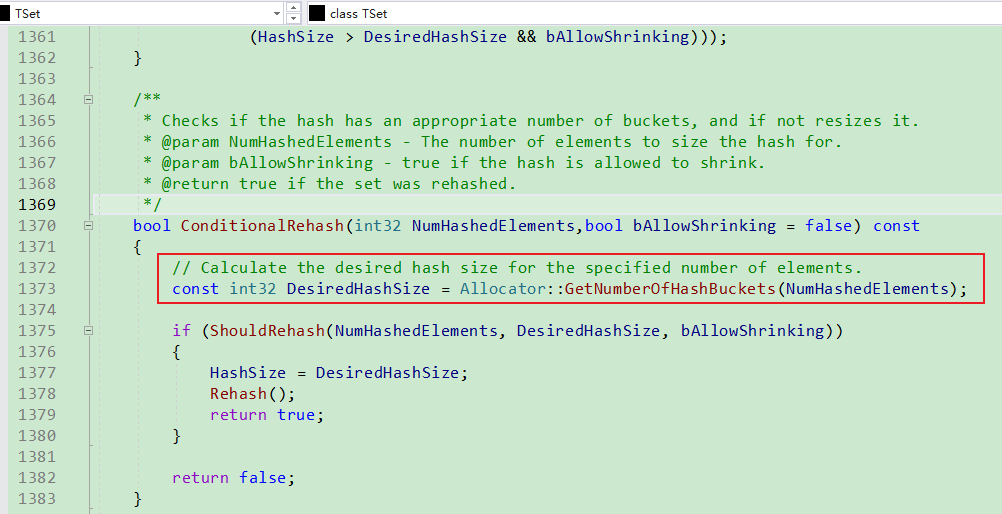
Rehash
- 释放HashArray所有元素
- 重建HashArray
- 将HashArray中元素设置为默认值.
- 遍历ElementArray, 重建HashArray.
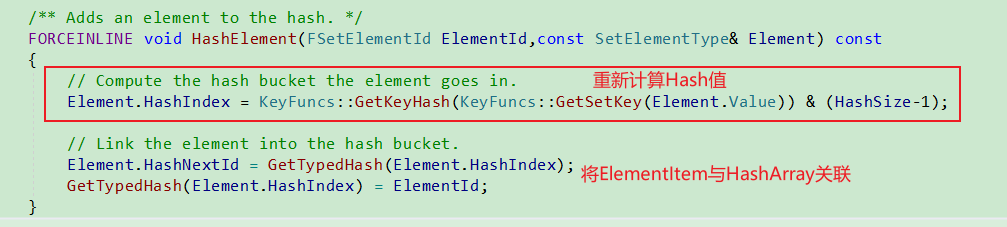
TSet.HashElement核心逻辑, 如下代码可以理解为:
对于任意新添加的元素Element, 重新计算其HashIndex,
将Element.Next设置为HashArray[HashIndex],
即Element.Next指向旧的ElementIndex,
然后更新HashArray[HashIndex],
将其设置为新的ElementIndex. 经过如上分析可知,
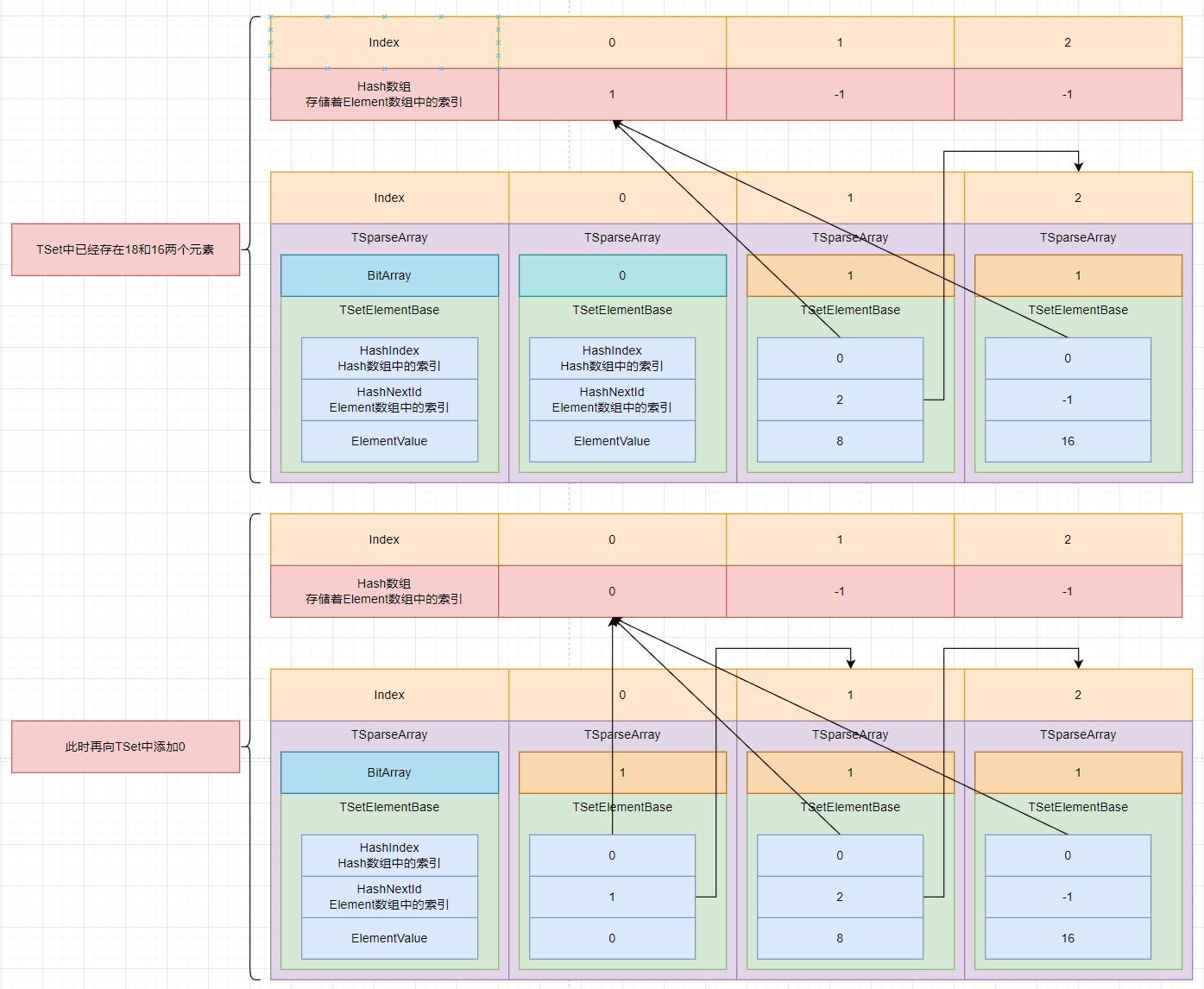
如果将Element插入到自己所在链表中会造成什么样的结果呢? 死循环:
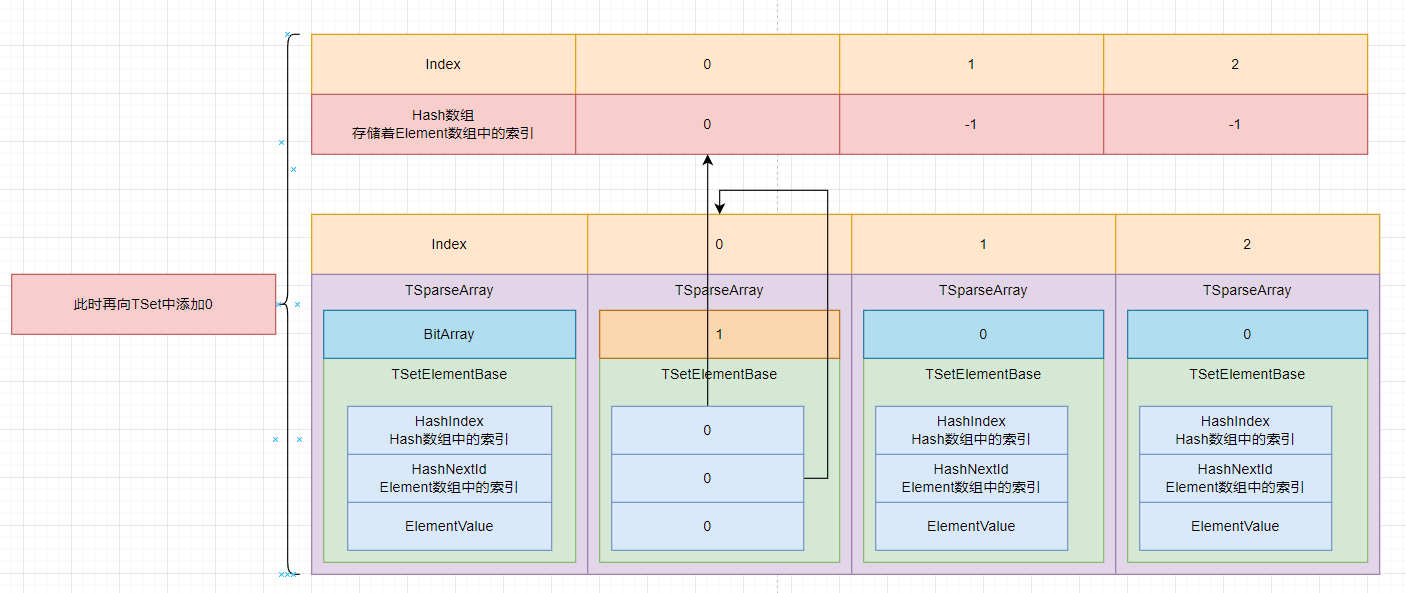
在TSet中, 不会将一个Element插入到自己链表头部. 所以不会有死循环.

什么时候进行Rehash呢?
一般而言根据Element的数量计算是否需要Rehash.
根据Element数量计算出目标数量(RoundUpToPowerOfTwo),
如果目标数量大于当前Hash数量, 就进行扩容.
- 添加新元素
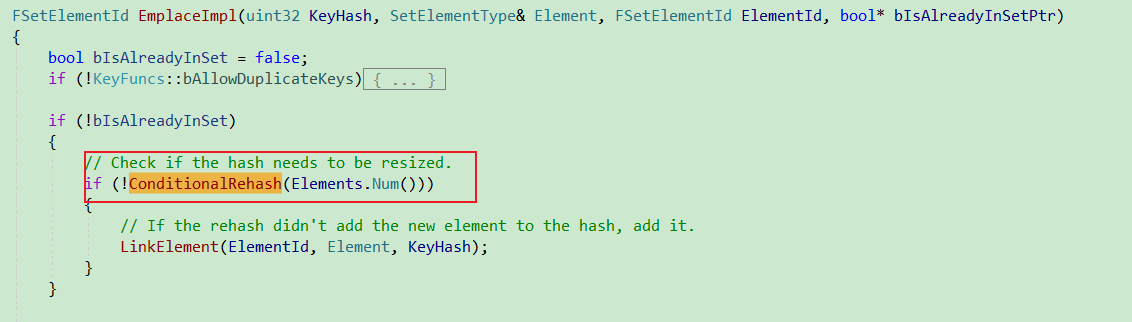
- 排序
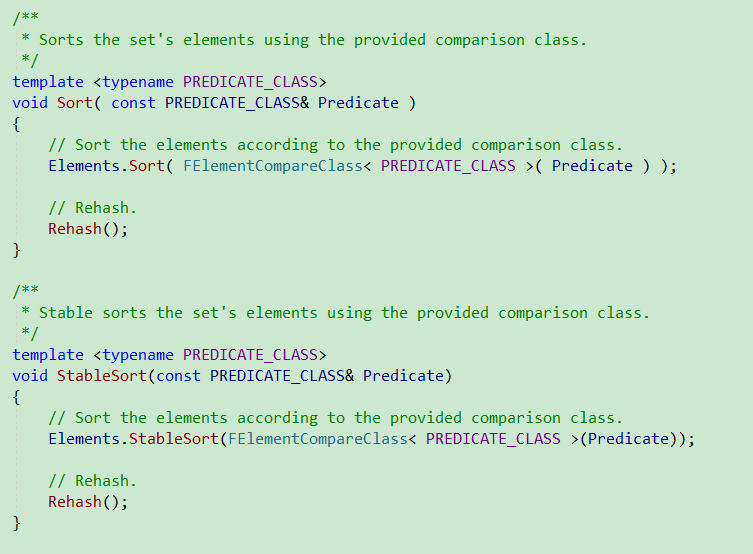
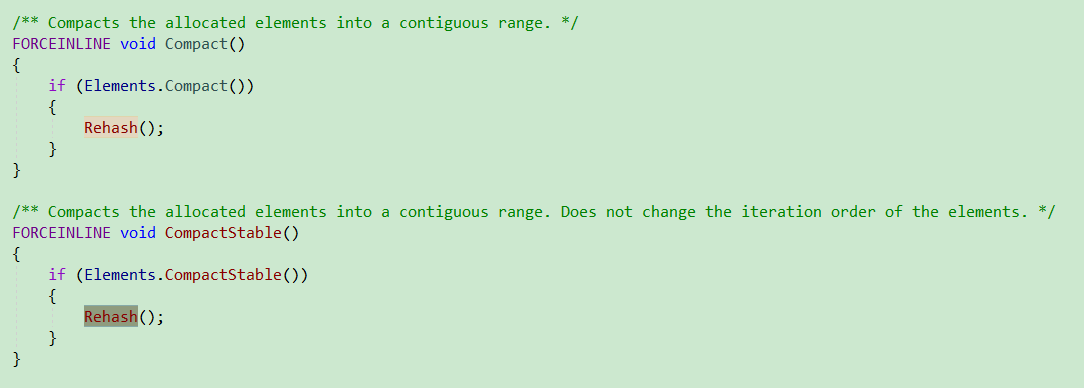
- Empty
- Compact
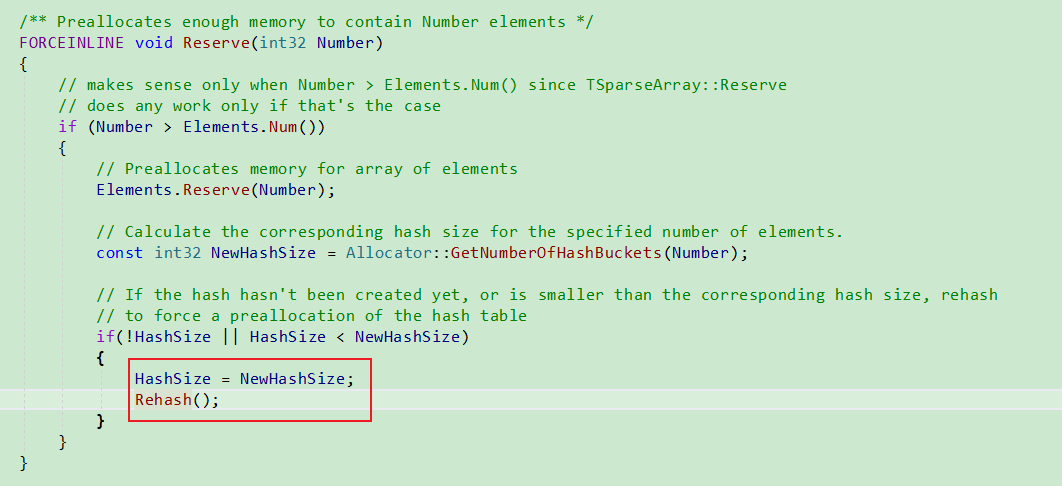
- Reserve
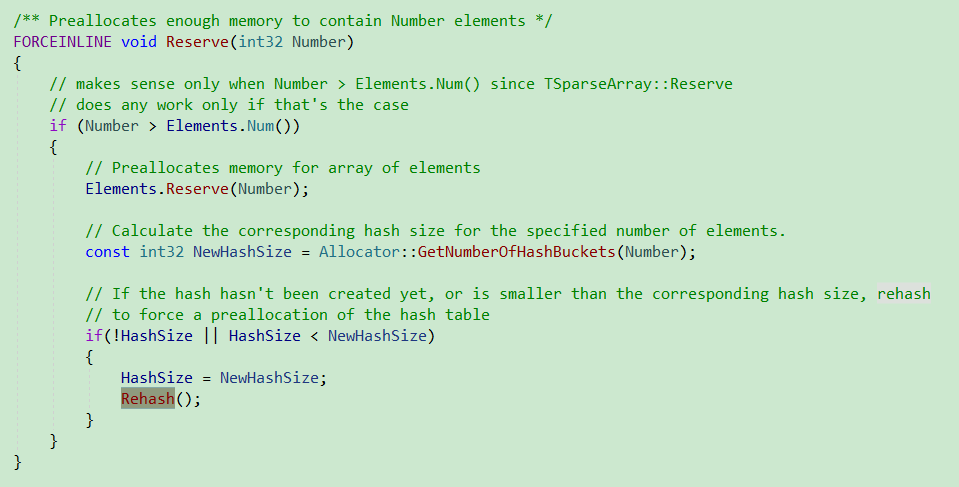
HashArray扩容
Reserve时候会进行扩容.
在添加元素时, 会按需进行扩容.
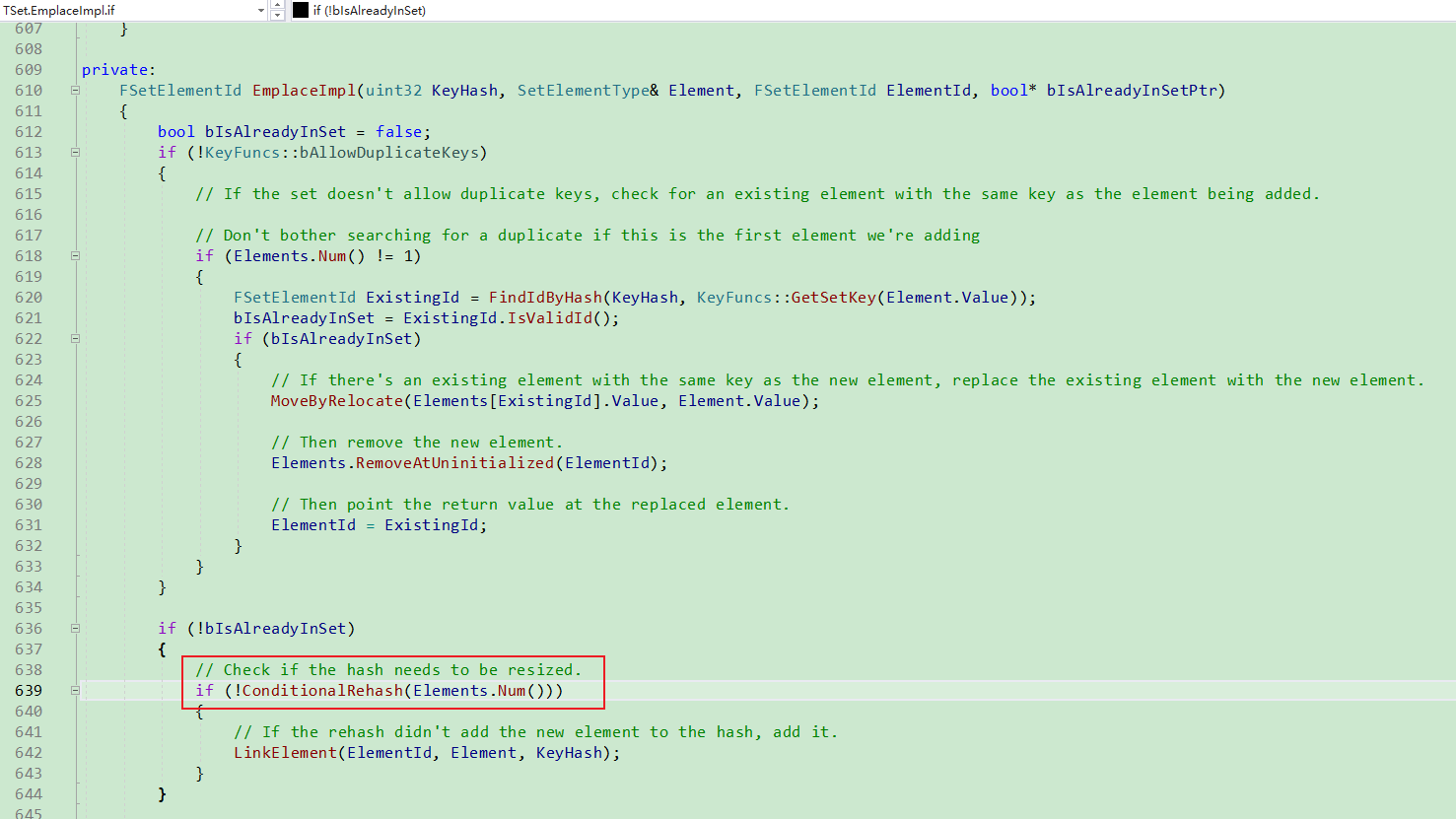
扩容的时候, 要执行Rehash.
ElementArray扩容
Reserve时候会进行扩容.
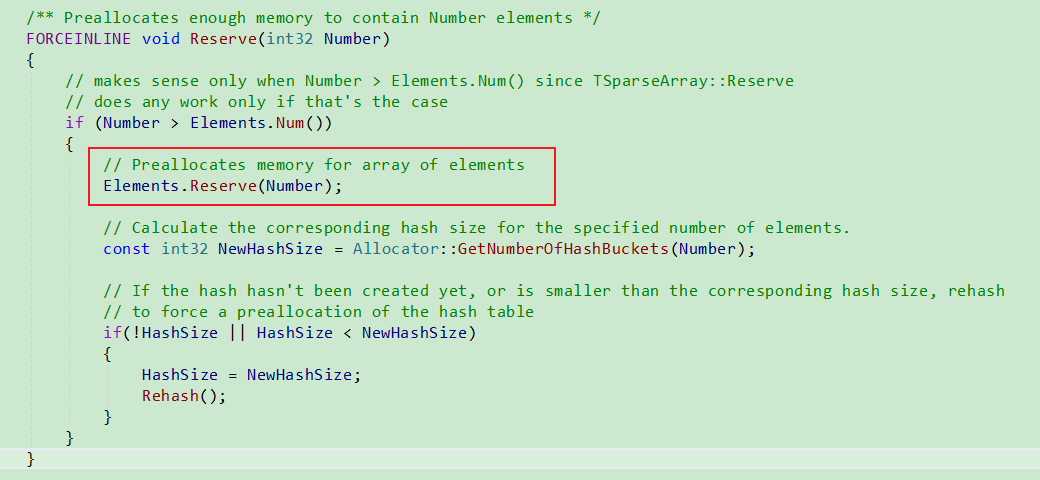
每当添加元素时候, 会按需进行扩容.
优化
性能消耗点: 在Add时候, 会进行一次GetTypeHash计算,
并与链表中元素进行比较. 假设HashArray大小为16,
那么每次添加元素的Hash值恰好是16的倍数, 则会形成单链表,
比较结果如下:
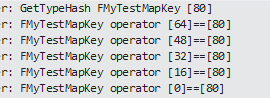
那么我们怎么才能节省性能呢?
可以将GetTypeHash生成的KeyHash存储在结构体内部,
只生成一次, 每次比较时候优先比较KeyHash, 如果KeyHash相同,
再比较具体内容. 如果我们能假定生成的KeyHash一定是唯一的,
那么只要比较其KeyHash就可以了.
但是尽量不要用operator ==,
可以仿照DefaultKeyFuncs定制BaseKeyFuncs,
最好进行前向声明, 这样大家就能直接用了.

前向声明参考: